In de eerste twee blogs van deze reeks hebben we het gehad over het grote strategische verhaal achter de Agentic Enterprise, en over de twee AI-producten die Snowflake heeft gebouwd voor kenniswerkers en developers. Maar er is een derde laag die minstens zo belangrijk is, en die in de hype rondom AI-producten te snel wordt overgeslagen: het fundament.
Want CoWork en Coco zijn alleen zo goed als de data waarop ze draaien. En die data is alleen betrouwbaar als de architectuur eronder klopt. Snowflake maakte op de Summit van 2026 een reeks aankondigingen die precies dat fundament versterken. Streaming, governance, security en interoperabiliteit. Geen glamoureuze onderwerpen, maar wel de reden waarom de AI-beloften uit blog 1 en 2 dit keer echt waargemaakt kunnen worden.
DataStream: einde aan de aparte streaming-stack
Een van de hardnekkigste problemen in moderne data-architecturen is dat realtime data en batch-data twee aparte werelden zijn. Teams bouwen en beheren een Kafka-cluster naast hun dataplatform, met alle complexiteit, kosten en latentie die daarbij horen.
DataStream lost dat op. Het is een volledig beheerde, Kafka-compatibele streamingservice die data direct landt in Snowflake- of Iceberg-tabellen, zonder aparte broker. Dat betekent dat je event-data, sensordata, clickstreams of transactiedata realtime beschikbaar hebt in hetzelfde platform als je historische data, zonder tussenliggende systemen.
Voor agentic AI is dit cruciaal. Agents die alleen op dagelijkse batches draaien, kunnen geen realtime beslissingen nemen. Met DataStream wordt het mogelijk om agents te bouwen die reageren op data zoals die binnenkomt, niet op data van gisterochtend.
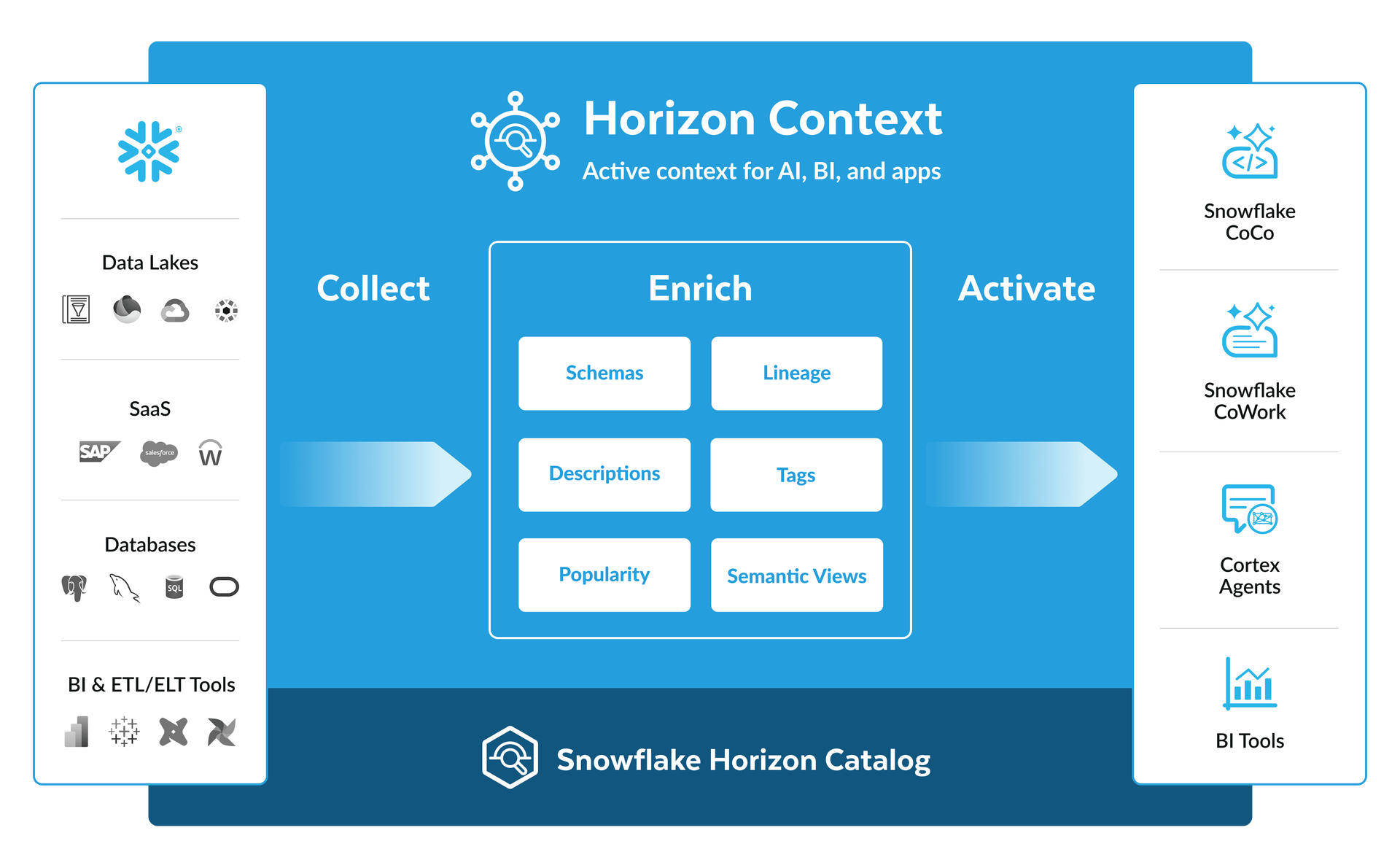
Horizon: context voor AI die je kunt vertrouwen
Data alleen is niet genoeg voor betrouwbare AI. Een agent die weet dat omzet vorig kwartaal 4,2 miljoen euro was, maar niet weet welke definitie van "omzet" daarbij hoort, hoe die berekend is, of welke systemen erin zijn meegenomen, geeft antwoorden die technisch kloppen maar inhoudelijk misleidend kunnen zijn.
Horizon is Snowflake's antwoord op dat probleem. Het is de universele objectcatalogus en het besturingsplatform dat alle data in en buiten Snowflake van context voorziet. Semantiek, lineage, menselijke annotaties: alles wat een AI-agent nodig heeft om niet alleen data te lezen, maar te begrijpen.
De nieuwe Horizon Context-laag gaat nog een stap verder. Het geeft agents een compleet, verrijkt beeld van het gehele data-estate, ook van data die buiten Snowflake staat. Dat maakt AI-antwoorden betrouwbaarder, omdat het model niet alleen cijfers ziet maar ook de betekenis, herkomst en validatiegeschiedenis ervan.
Voor onze klanten is dit de directe vertaling van wat wij altijd hebben gezegd over semantische lagen en datakwaliteit: garbage in is garbage out, ook als het garbage is van 4,2 miljoen euro. Horizon maakt het mogelijk om die context systematisch te beheren en te delen met alle AI-systemen die erop draaien.
Trust Center: agents als digitale medewerkers
Een van de meest treffende uitspraken van de Summit was deze: "Agents moeten worden behandeld als digitale medewerkers, met toegangsrechten, grenzen en audittrails vanaf dag één."
Dat is precies wat het Trust Center biedt. Het AI-securitypakket bevat guardrails tegen prompt injection, agent policies die bepalen wat agents wel en niet mogen doen, en end-to-end zichtbaarheid over alle acties die agents ondernemen.
In de praktijk betekent dit dat je een agent kunt definiëren die klantdata mag lezen, maar geen data mag wegschrijven naar externe systemen. Of een agent die financiële rapporten mag samenstellen, maar geen goedkeuringen mag geven. Die grenzen zijn niet alleen technisch verankerd, maar ook volledig auditeerbaar. Elk datapunt dat een agent heeft gebruikt, elke actie die is ondernomen, is terug te vinden.
Voor Nederlandse organisaties die werken met privacygevoelige data, financiële rapportages of gereguleerde sectoren is dit geen nice-to-have. Het is de voorwaarde waaronder agentic AI überhaupt verantwoord ingezet kan worden.
Lakehouse en Iceberg: geen vendor lock-in
De vierde pijler is interoperabiliteit. Snowflake's Lakehouse is nu algemeen beschikbaar, gebouwd op Apache Iceberg v3 met ondersteuning voor meerdere query-engines. De Horizon Catalog implementeert de open Apache Polaris-standaard, wat betekent dat governance-policies meegaan als data wordt bevraagd vanuit een andere engine.
In gewone taal: je kunt jouw Iceberg-tabellen bevragen vanuit Snowflake, maar ook vanuit Spark, Trino of een andere engine, zonder data te hoeven kopiëren en zonder governance te verliezen. Dat elimineert een van de grootste bezwaren tegen platform-consolidatie: de angst om vast te zitten aan één leverancier.
Voor organisaties die meerdere query-engines gebruiken, of die overwegen te consolideren, is dit een strategisch relevant signaal. Je kunt de voordelen van het Snowflake-platform benutten zonder je te binden aan een architectuur die geen flexibiliteit toelaat.
MCP-connectors: agents die ook buiten Snowflake actie ondernemen
Agents hebben weinig aan inzichten als ze die inzichten niet kunnen omzetten in acties buiten het dataplatform. Snowflake's MCP-connectors en gateway maken het mogelijk om agents te verbinden met systemen als Salesforce, Slack en e-mail, vanuit één enkel beheerpunt.
Het slimme detail: Snowflake's governance, inclusief toegangscontrole en auditlogs, strekt zich uit over die externe acties. Als een agent een bericht stuurt in Slack op basis van een data-signaal, is dat traceerbaar en instelbaar. Dat maakt het verschil tussen een agent die autonoom handelt en een agent die autonoom handelt binnen de grenzen die jij hebt gesteld.
De kern van het verhaal
De drie blogs in deze serie vertellen samen één verhaal. Agentic AI is niet langer een experimenteel concept. De technologie is beschikbaar, de architectuur is volwassen genoeg, en de governance-tools zijn er om het verantwoord te doen.
Maar het werkt alleen als het fundament klopt. DataStream zorgt dat data realtime beschikbaar is. Horizon zorgt dat AI begrijpt wat die data betekent. Het Trust Center zorgt dat agents handelen binnen de grenzen die jij stelt. En Lakehouse met Iceberg zorgt dat je dat allemaal kunt doen zonder vast te zitten aan één leverancier.
Voor DDBM betekent dit dat wij onze klanten nu kunnen helpen met een concreet pad: van een datastrategie-assessment naar een eerste agentic use case, met de juiste technologieën als fundament.
Wat jij nu kunt doen
Begin met een pilot op DataStream en Horizon Context. Kies een use case waarbij realtime data en betrouwbare context samen nodig zijn, en valideer of het platform de antwoorden levert die jij verwacht.
Implementeer het AI-securitypakket van het Trust Center voordat je agents productie-klaar maakt. Definieer welke agents welke rechten hebben, en zorg dat het audittrail van dag één staat.
Overweeg de overstap naar Adaptive Compute en Iceberg v3. Niet als grote migratie, maar als stap in de richting van een architectuur die flexibel, kostenefficiënt en toekomstbestendig is.
En neem contact op als je wilt sparren over hoe dit eruitziet voor jouw specifieke omgeving. Wij helpen onze klanten al jaren met het strategisch inzetten van Snowflake, en de aankondigingen van Summit 2026 maken dat gesprek een stuk concreter.