By Dimitris Lampriadis on 22 Apr, 2026

Introduction
Defining the Data Quality Framework
In the context of modern analytics engineering, a Data Quality Framework is a systematic set of automated safeguards designed to ensure that data remains accurate, reliable, and "fit for purpose" as it moves through the pipeline.
It’s a set of rules and tools that check your work at every step—from the moment you write a line of code to the moment the data hits a dashboard.
The framework embeds validation directly into the development lifecycle. By utilizing dbt for modular testing and documentation, pre-commit hooks to catch syntax errors or missing metadata before code even leaves the developer's machine, and Slim CI to dynamically test only the modified models. Engineers use these tools to fail fast.
This ensures that any data violating business logic or schema integrity is intercepted and blocked before it can ever reach a production dashboard or influence a business decision.
This project involved migrating a global logistics leader from Oracle to Snowflake. We rebuilt their data foundation using dbt Core, Dagster for the orchestration, and Flyway, all running on Docker and landing in Snowflake.
For a company moving goods by road, sea, and air, data accuracy is a physical requirement. Bad data stalls shipments and disrupts supply chains for millions of customers. We built this framework to ensure every business decision rests on reliable, automated validation.
The framework pillars
Every company has different needs, but for this project, we built a framework that focused on two things: Trusting our Code (making sure it’s clean and following rules) and Trusting our Data (making sure the numbers actually make sense). We wanted a system that was invisible but invincible.
The "Before" state: The cost of manual chaos
Since I joined the project most of the processes were manual, everyone had their own way of writing code, and there were no real standards. This made the quality of the development process, but also the data itself unreliable and untrustworthy. Before the framework, the team spent 20% of every sprint fixing syntax errors and re-running failed production jobs. We were burning warehouse credits on code that was destined to fail.
The development process looked like this:

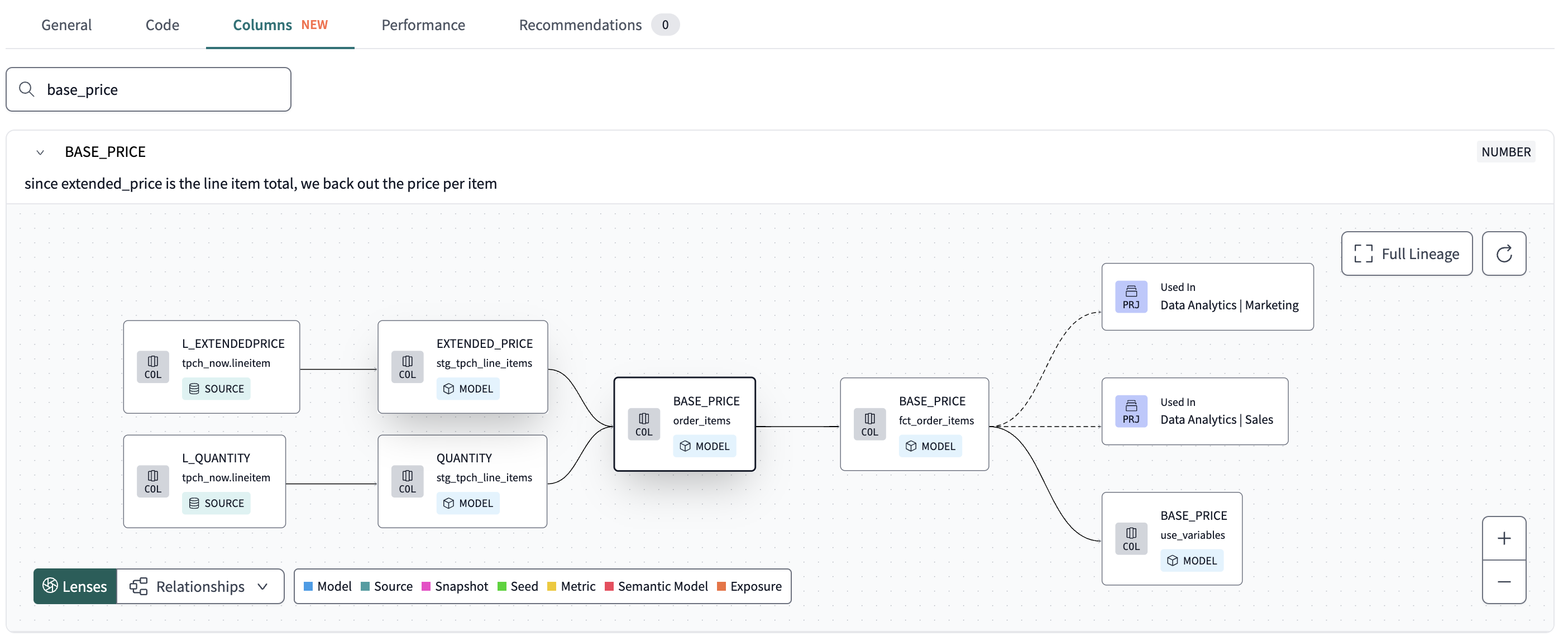
Even after a model was developed and pushed to production there weren’t any automatic tests in place, rather than a set of manual sql scripts that would test the data integrity of the new table.
Goal
We implemented this framework to kill syntax errors at the source. We needed to enforce metadata standards and business logic transformations while ensuring continuous integration for new developments.
Trusting our Code
Pre-commit hooks
Standardization starts on the local machine. Pre-commit hooks was the to-go tool that would enable the standardization of the code, and automating the quality control during development. The tools that were selected to be included in the pre-commit hooks were:
-
SQLFluff 1: This tool enforces SQL styling and formatting. It prevents "creative" indentation and non-standard capitalization.
-
Ruff 2: We use this for Python linting. It keeps our utility scripts clean and production ready.
-
dbt-checkpoint 3: This validates model properties. It ensures every model has a description and a primary key test before the code moves to the repository. dbt-checkpoint is a package that enables dbt related pre-commit hooks.
Part of the config file of the pre-commit hooks looked like:
These checks run on every commit. If the code fails a rule, the system blocks it. We mirrored these hooks in the CI/CD pipeline to ensure code quality remains consistent across all developer environments, which will be briefly explained further below. This strategy reduces GitLab pipelines' run times and saves compute resources in the data warehouse.
Eventually, the result of the above implementation in the development process looked like:
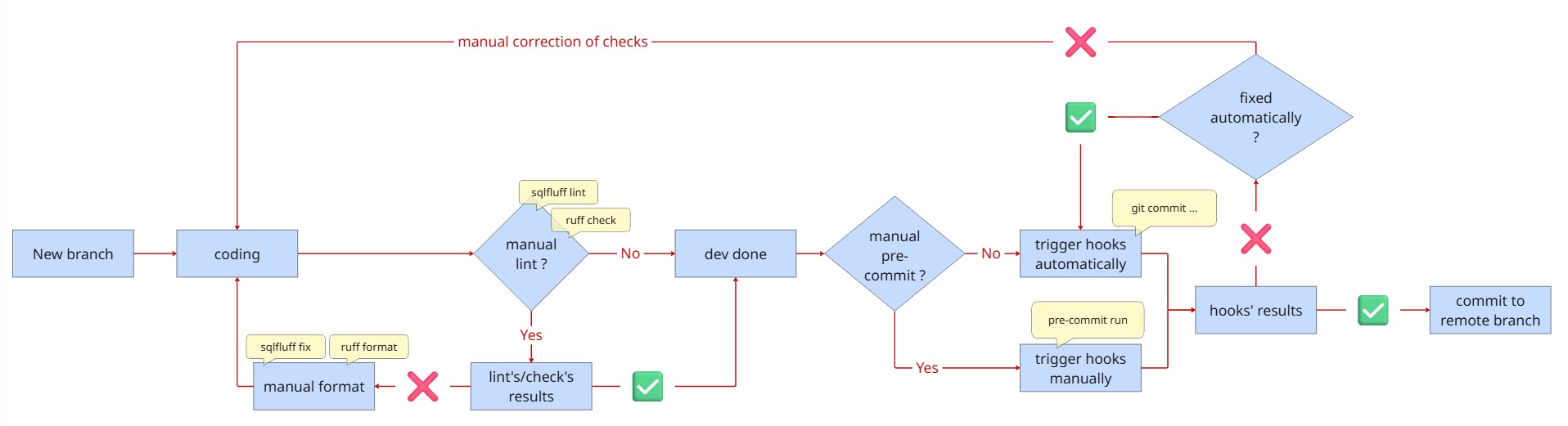
CI/CD
Local pre-commit hooks only provide the first layer of trust. CI/CD 4 (Continuous Integration/Continuous Delivery) pipeline completes the development cycle. Local hooks provide the first layer of trust; the CI/CD pipeline completes it. The system automates the build and test cycle, stopping engineers from bypassing local checks when they open a Merge Request. The image below places the pre-commit and the CI/CD pipelines implemented at the client in a context. The client had already in place a GitLab repository.

When a developer passes all local checks and pushes code to a remote branch, they open a Merge Request. This action triggers the GitLab pipeline. The system runs checks to stop engineers from bypassing local hooks.
Slim CI and state comparison
The most critical part of this pipeline is Slim CI 5. Traditional CI pipelines often test the entire project, which wastes time and warehouse credits. Slim CI uses a "state comparison" method. It compares the new code against the last successful production run to identify only the modified or downstream models.
The pipeline executes these specific models in a dedicated "CI schema." This isolation allows the team to verify that the new business logic works correctly without affecting production data or existing dashboards. The pipeline must pass every check before the "Merge" button becomes active. This automation ensures that no broken code ever reaches the production environment.
This strategy allows the pipeline to trigger specific dbt tests based on the development stage. Understanding when these tests run requires a clear map of the testing layers.
Standardizing the development process and trusting the code stopped the chaos, but logic checks don't catch bad data from sources. Part two will examine our strategy for 'Trusting our Data.' I’ll detail how we deployed Elementary for anomaly detection and dbt-expectations to handle schema validation, finally eliminating the manual SQL scripts that used to guard our warehouse.
At DDBM we help companies build modern data architectures using tools like Snowflake, dbt, and Matillion. If you are curious about how AI-augmented data engineering could help your team, feel free to reach out.
- https://www.sqlfluff.com/
- https://docs.astral.sh/ruff/
- https://pre-commit.com/
- https://www.infoworld.com/article/2269266/what-is-cicd-continuous-integration-and-continuous-delivery-explained.html
- https://docs.getdbt.com/best-practices/best-practice-workflows?version=1.12#run-only-modified-models-to-test-changes-slim-ci

Deferring in dbt Core: Save Yourself Time and Headaches
Modern Data Stack in One Day