
Door Emre Oktay op 17 Mar, 2024
Gegevens combineren in Tableau
Als het gaat om het combineren van gegevens in Tableau, hebben we drie opties. Joins, Relaties en Blends. Elke techniek heeft zijn eigen voordelen en beperkingen. Joins zijn de meest traditionele manier om gegevens te combineren. We combineren tabellen met vergelijkbare rijenstructuren tot een grotere fysieke tabel. Relaties zijn de standaard manier om gegevens in Tableau dynamisch te combineren. Waar joins tussen tabellen worden gecreëerd wanneer ze worden gebruikt in views. Best gebruikt wanneer tabellen verschillende detailniveaus hebben. Beide methoden worden geconfigureerd binnen de gegevensbron. Er is echter een andere methode om gegevens te combineren die een beetje anders is: Blenden. In deze blog zullen we kort onderzoeken wat blends zijn. Daarna bespreken we een aantal veelvoorkomende problemen waar gebruikers tegenaan kunnen lopen en een aantal oplossingen.
Wat zijn Blends?
Het enige kenmerk dat blends anders maakt dan Joins en Relationships is het feit dat we, in plaats van gegevens binnen een gegevensbron te combineren, verschillende gegevensbronnen combineren. Onthoud dat gegevensbronnen bestanden zijn met alle verbindingsinformatie naar verschillende bestanden/servers plus alle aanpassingen die je maakt in Tableau. Blends combineren gegevens niet rechtstreeks vanuit de bron. Maar worden uitgevoerd op een sheet-to-sheet basis. Daardoor zijn ze ook niet publiceerbaar zoals echte gegevensbronnen.
Net als bij Joins en Relationships maken we echter nog steeds een gemeenschappelijk veld om de twee bronnen aan elkaar te koppelen. Als de kolomnaam hetzelfde is in de twee gegevensbronnen, gebruiken we die velden als gemeenschappelijke link.

Eveneens vergelijkbaar met joins, is het blenden van gegevens vergelijkbaar met een linker join. We behouden alle informatie in de primaire gegevensbron. Maar alleen de overeenkomende resultaten uit de secundaire gegevensbronnen worden getoond. De primaire gegevensbron wordt gemarkeerd met een blauw vinkje en de secundaire gegevensbronnen krijgen na het samenvoegen een oranje vinkje. Een groot verschil tussen joins en blends is ook dat bij joins de gegevens worden samengevoegd en vervolgens geaggregeerd. Bij blends worden de gegevens samengevoegd en vervolgens samengevoegd.

Bekijk deze bron over Blend Your Data voor meer details over hoe je een Blend kunt configureren.
Het belangrijkste om in gedachten te houden is dat Blenden alleen moet worden uitgevoerd als er geen manier is om dezelfde verbindingen binnen één gegevensbron te maken. Dit komt door de beperkingen die deze techniek met zich meebrengt in vergelijking met Joins of Relaties. Laten we eens kijken naar enkele van deze beperkingen en mogelijke oplossingen voor de problemen.
Veelvoorkomend probleem #1: Kan de secundaire gegevensbron niet blenden omdat een of meer velden een niet-ondersteunde aggregatie gebruiken
De aggregatiemethoden COUNTD, MEDIAN en andere niet-additieve aggregatiefuncties kunnen ervoor zorgen dat velden ongeldig worden. Deze fout treedt meestal op als de twee bronnen zich op verschillende aggregatieniveaus bevinden.

Bovendien kan deze fout om verschillende redenen optreden. Om niet-additieve aggregaten van de primaire bron te gebruiken, moeten de gegevens afkomstig zijn van een relationele database die het gebruik van tijdelijke tabellen toestaat. Voor gebruik in secundaire gegevensbronnen moet het koppelingsveld uit de primaire gegevens worden opgenomen in de weergave. Deze fout kan ook optreden bij het gebruik van LOD-expressies van de secundaire gegevensbron.
Oplossingen:
- Wijzig de aggregatie: U kunt het aggregatieniveau van het veld in de secundaire gegevensbron wijzigen zodat het overeenkomt met het niveau van het veld in de primaire gegevensbron. Als de primaire gegevensbron bijvoorbeeld een dagelijkse aggregatie heeft, kunt u de secundaire gegevensbron wijzigen zodat deze overeenkomt met dat aggregatieniveau.
- Een berekend veld maken: U kunt een berekend veld maken in de secundaire gegevensbron dat een aggregatie gebruikt die wordt ondersteund voor blenden. Als de primaire gegevensbron bijvoorbeeld de aggregatie SUM gebruikt, kunt u een berekend veld maken in de secundaire gegevensbron dat ook de aggregatie SUM gebruikt.
- Gebruik een gegevensextract: Het maken van een gegevensextract kan soms helpen bij het oplossen van niet-ondersteunde aggregatiefouten door een statische, geaggregeerde weergave van de gegevens te maken die beter geschikt is voor blenden.
- Gebruik een join in plaats van blending: Als samenvoegen niet nodig is voor je analyse, kun je in plaats daarvan proberen de gegevensbronnen samen te voegen. Dit kan soms helpen om de niet-ondersteunde aggregatiefout op te lossen.
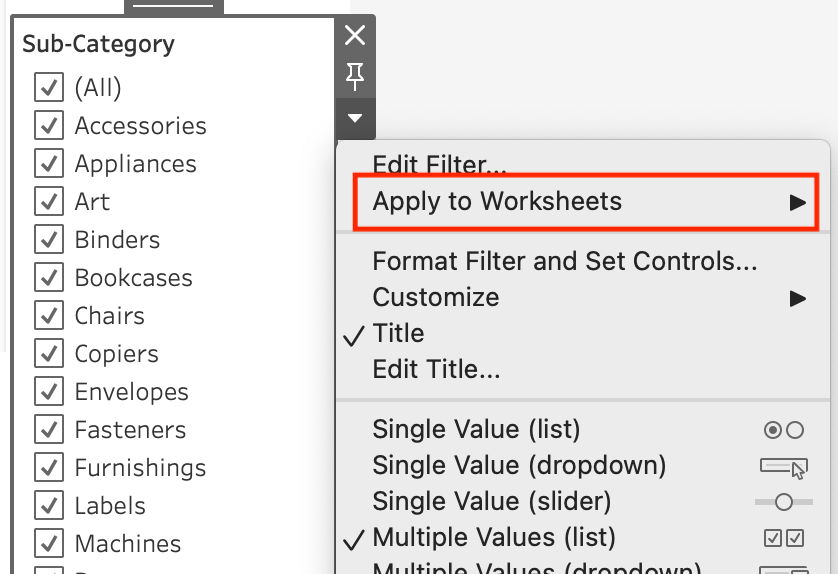
Veelvoorkomend probleem #2: "*"
Als er na het samenvoegen meerdere overeenkomende dimensiewaarden uit beide bronnen komen, zien we een sterretje (*). Het is net alsof we een dimensie hebben gemaakt met meerdere waarden en attributen. Zoals ATTR([Subcategorie]).

Oplossingen:
- Vermijd dit probleem door te zorgen voor slechts één overeenkomende waarde tussen je bronnen. Het toevoegen van een veld met een hogere granulariteit van de primaire bron kan het probleem oplossen. Bijvoorbeeld "Stad" gebruiken in plaats van "Staat".
- Herbouw je weergave en verwissel de primaire en secundaire gegevensbronnen. De bron met een hogere mate van granulariteit zou de primaire bron moeten zijn.
Veelvoorkomend probleem #3: Omgaan met NULL-waarden na blenden
De reden voor het verschijnen van NULL waarden na het blenden kan verschillende redenen hebben. Er kan een mismatch zijn in behuizing en gegevenstypes tussen de bronnen. Of dat de secundaire gegevensbron geen waarden bevat voor de overeenkomstige waarden die uit de primaire bron komen.
Oplossingen:
- Controleer of de casing en de datatypes van velden hetzelfde zijn tussen de gegevensbronnen: Gebruik berekeningen zoals PROPER(), UPPER, LOWER() om de casing aan te passen. Als het datatype niet overeenkomt, wijzig het dan in het gegevensvenster met de pictogrammen naast de veldnamen. Of schrijf berekeningen voor typeconversie zoals STR() of INT().
- Gebruik het tabblad Gegevensbron: Op het tabblad Gegevensbron kunt u met de rechtermuisknop op het gemixte veld klikken en "Ontbrekende waarden vervangen" selecteren om nulwaarden te vervangen door een opgegeven waarde. Je kunt ook "Vullen" selecteren om nulwaarden op te vullen met de waarde van de vorige of volgende cel die niet leeg is.
- IFNULL-functie gebruiken: U kunt de IFNULL-functie gebruiken om nulwaarden te vervangen door een opgegeven waarde in een berekend veld. Je kunt bijvoorbeeld een berekend veld maken dat controleert of een veld null is en een standaardwaarde retourneert als dat zo is.
- Functie ISNULL gebruiken: Je kunt de functie ISNULL gebruiken om een berekend veld te maken dat nulwaarden in het gemengde veld identificeert. Je kunt dit berekende veld dan gebruiken in je analyse om op de juiste manier om te gaan met nulwaarden.
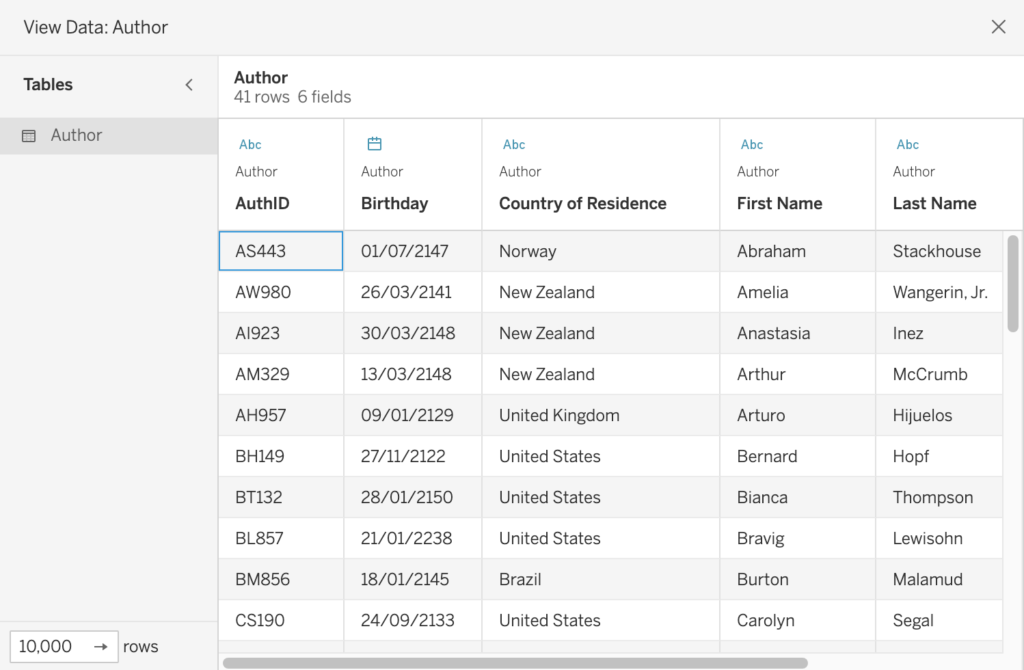
Relaties, Joins, Unions en Blends begrijpen in Tableau - The Information Lab Nederland
Top 3: Trucs voor het werken met meetnamen en waarden in Tableau




