
Door Reinier van Elderen op 30 Apr, 2025
Het beheren van te veel tools kan al snel een hoofdpijn worden, vooral bij het bouwen van complexe datapijplijnen. Tijdens een van mijn laatste projecten heb ik geëxperimenteerd met het gebruik van Python stored procedures in Snowflake. Ik was op zoek naar een manier om de ontwikkeling te vereenvoudigen en het aantal verschillende applicaties te verminderen die nodig zijn om een ingestion pipeline te bouwen. Met taken, externe toegangsintegraties, opgeslagen procedures en rekenbronnen op één locatie heeft Snowflake de potentie om het allemaal te doen. Tijdens de ontwikkeling ontdekte ik echter dat het gebruik van deze methode een aantal nadelen heeft.
De voordelen: Gecentraliseerde logica
Snowflake stored procedures geschreven in Python zijn op papier een game-changer.
- Alle logica op één plaats Bedrijfslogica rechtstreeks in Snowflake hebben vereenvoudigt de architectuur. U hoeft niet langer te jongleren tussen transformatielogica in dbt, orkestratie in Airflow en databaselogica in Snowflake. Alles draait op één plek, met minder latentie en zonder verplaatsing van gegevens.
- Python in het Warehouse Python is bekend bij de meeste data engineers, dus het gebruik van Snowpark Python in stored procedures zorgt voor meer expressieve, onderhoudbare en krachtige logica. De ondersteuning voor algemene bibliotheken en ingebouwde Snowpark-functies maakt dit bijzonder aantrekkelijk.
- Draait op Snowflake-bronnen Aangezien de code direct op de Snowflake-rekenbronnen draait, hoeft u geen afzonderlijke rekenkracht te leveren of zich zorgen te maken over het opzetten van extra orkestratieframeworks. Dit betekent dat al uw kosten zijn verbonden aan één platform, wat de kosten en ontwikkeling vereenvoudigt.
De nadelen: één grote rommelige string
Maar de dagelijkse ontwikkelaarservaring? Dat is waar de barsten zichtbaar worden.
- Een grote String Blob Wanneer je werkt met stored procedures in een andere taal dan SQL, creëer je een volledige Python-functie in een SQL stringblok. Dit resulteert in inspringingsproblemen en geen syntax highlighting in de Snowflake UI. Zelfs als u lokaal ontwikkelt, moet u vaak grote Python-blokken kopiëren naar SQL-scripts. Dit ontwikkelproces is onhandig en foutgevoelig.
- Versiecontrole bestaat niet Stored procedures leven in de Snowflake database. Dat betekent geen native Git integratie, geen geschiedenis bijhouden en geen PR reviews tenzij je de SQL string exporteert naar een bestand en het extern beheert. Zelfs dan is het lezen van diffs in gigantische string-blokken lastig. Je Python IDE gaat dat blok ook niet linten of testen zoals normale code.

Ziet er eenvoudig uit, toch? Stel je dit nu eens voor bij 500+ regels logica.
Een mogelijke oplossing? @sproc decorator
Een tijdje geleden introduceerde Snowflake ondersteuning voor de @sproc decorator als onderdeel van de Snowpark voor Python API. Dit is een enorme stap in de richting van betere onderhoudbaarheid.
Met @sproc kunt u een opgeslagen procedure definiëren als een standaard Python-functie in een Python-bestand buiten SQL en deze rechtstreeks registreren in Snowflake. Het gebruik van deze decorator maakt het volgende mogelijk
- Schone, testbare Python-code (niet één grote string)
- Goed gebruik van IDE-functies tijdens het ontwikkelen (linting, autocomplete, etc.)
- Werkelijk versiebeheer via Git
Maar zelfs met deze verbetering is de oplossing niet perfect. De ervaring van de ontwikkelaar is zeker verbeterd, maar er zijn nog steeds enkele tekortkomingen.
- Argumentnamen verdwijnen Een subtiel (maar vervelend) detail: argumentnamen van procedures zijn niet zichtbaar als ze eenmaal geïmplementeerd zijn. Dit betekent dat je, tenzij je grondig bent met documentatie, de originele code moet opzoeken om te onthouden wat elke parameter was.
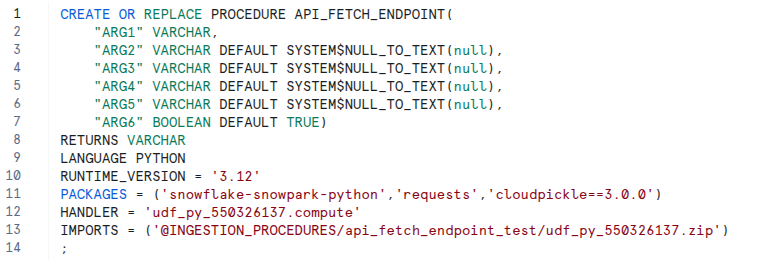
- Code is verborgen in Snowflake Als het codeblok eenmaal is geïmplementeerd, is de eigenlijke code niet zichtbaar in de Snowflake UI. De procedure verwijst naar een zip-bestand dat je functie bevat. Je kunt zien dat er een opgeslagen proces bestaat, maar niet wat het doet. Als je aan het debuggen bent of code probeert te controleren, zit je vast. Je zult moeten kijken waar de procedure is gemaakt in de git of externe documentatie.

Het gebruik van deze decorator zal de procedure die hierboven is gemaakt in snowflake veranderen in de onleesbare rotzooi hieronder wanneer deze is gemaakt met de @sproc decorator. Dit maakt het erg uitdagend om deze procedure te gebruiken en te begrijpen als een gebruiker alleen toegang heeft tot Snowflake.

Laatste gedachten
Python stored procedures in Snowflake zijn een veelbelovende functie en voor veel teams lossen ze al problemen op. Maar voor grootschalige productiecode is het er nog niet op het gebied van onderhoudbaarheid, zichtbaarheid en versiebeheer. Ik zou voorstellen om het te gebruiken voor kleine procedures met eenvoudige logica die geen versiebeheer vereisen.
Heb je soortgelijke problemen gehad met Python stored procedures in Snowflake, of heb je slimme oplossingen gevonden voor deze problemen, laat het me weten!

Sorteren met een parameter (in Tableau)
Dbt tips ; Kopieer geen beschrijvingen meer met Doc blocks




