
Door Lukas Bogacz op 22 Mar, 2023
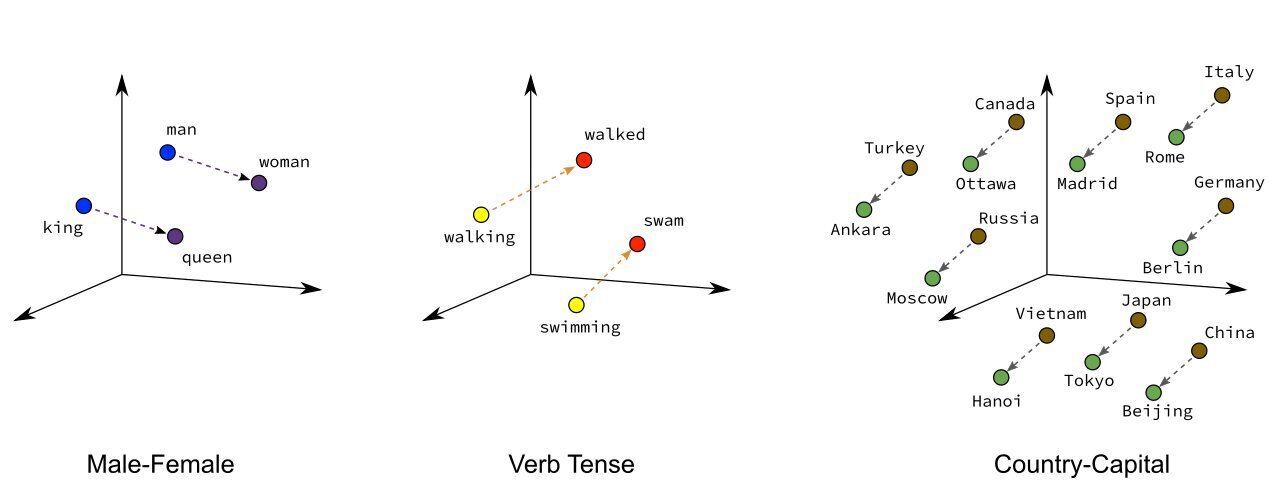
 h
h
 h
h



Delen
Volgende blog
Documenteren, waarom en hoe? -1 →
Tips & tricks: Alteryx Designer Dark Mode
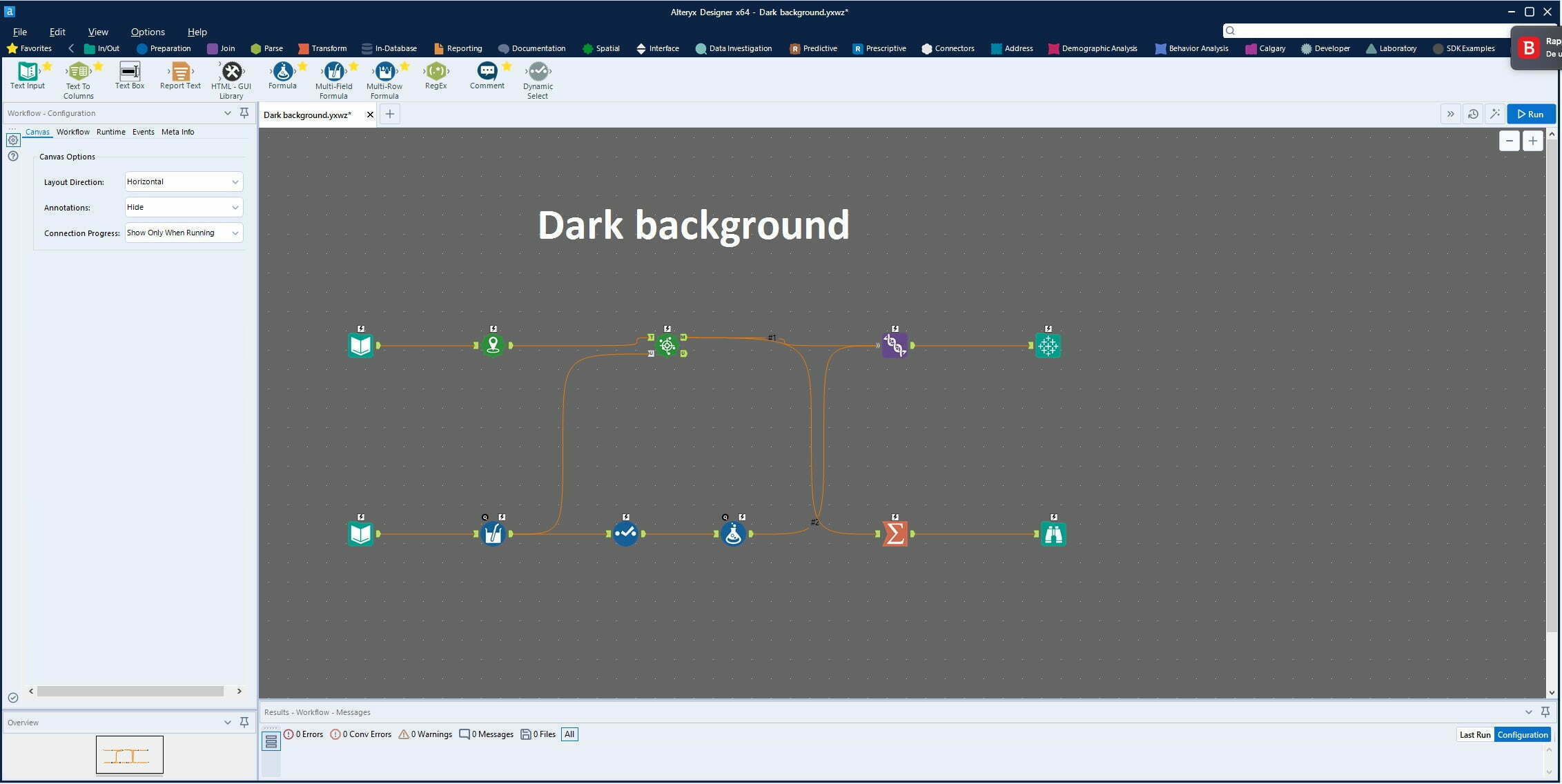
Tips & tricks: Alteryx Designer Dark Mode
22 Jan, 2020
1
min
Verschillende weken vergelijken in één overzicht -de maximale waarde van meerdere worksheets tonen- 4

Verschillende weken vergelijken in één overzicht -de maximale waarde van meerdere worksheets tonen- 4
15 Jun, 2022
3
min
De kleur van labels aanpassen in Tableau

De kleur van labels aanpassen in Tableau
21 Apr, 2022
1
min



