Door Darko Monzio Compagnoni op 29 Aug, 2024
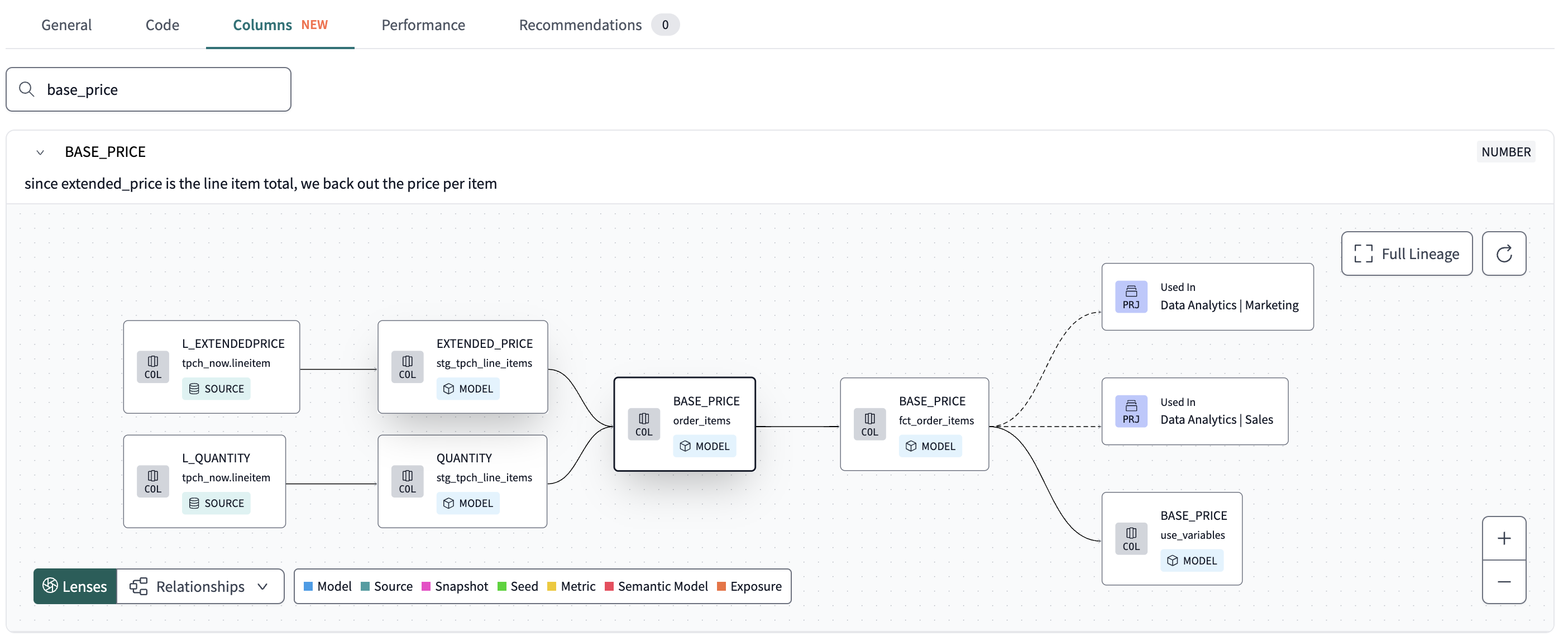
Onlangs heeft dbt (data build tool) Column-Level Lineage (CLL) geïntroduceerd binnen dbt Explorer. Dit biedt een gedetailleerd inzicht in de oorsprong en transformaties van gegevens op kolomniveau.
Wat is kolomniveau lineage (CLL)?
Column-Level Lineage is een krachtige functie die gedetailleerde lineage informatie biedt voor elke kolom binnen bronnen zoals modellen, bronnen of snapshots in een dbt project.
Met deze functie kunnen gebruikers de gegevensstroom volgen vanaf de oorsprong tot het gebruik in downstreamprocessen. Het is vooral handig om te begrijpen hoe elke kolom wordt getransformeerd of hergebruikt in verschillende stadia van gegevensverwerking.

Toegang tot kolom-afstammingsgegevens
Toegang tot CLL is eenvoudig voor gebruikers van dbt Cloud Enterprise:
- Navigeer naar het tabblad Kolommen op een Explorer resource detailpagina(model, bron of snapshot)
- Vouw de kolomkaart uit om de lineage informatie te bekijken
dbt Cloud werkt deze lineage bij na elke run in de productie- of staging-omgeving, met de nieuwste transformaties en bronnen voor elke kolom.
Praktische toepassingen van lineage op kolomniveau
1. Analyse van de hoofdoorzaak: Bij het oplossen van problemen met datapijplijnen helpt CLL bij het lokaliseren van de oorsprong van fouten. Bijvoorbeeld, het identificeren van een upstream niet-geteste kolom die een datatestfout veroorzaakte in een dbt-model wordt eenvoudiger met CLL, waardoor oplossingen sneller kunnen worden opgelost.
2. Impactanalyse: Tijdens de ontwikkeling of bij het aanbrengen van wijzigingen in datamodellen kunnen analytics engineers CLL gebruiken om de bredere impact van hun wijzigingen te beoordelen. Dit inzicht minimaliseert onvoorziene problemen en stroomlijnt het beoordelingsproces voor pull requests.
3. Samenwerking en efficiëntie: Inzicht in kolom lineage verbetert de samenwerking tussen teamleden door duidelijk inzicht te geven in de afhankelijkheden van gegevens. Deze transparantie stelt analisten en engineers in staat om weloverwogen beslissingen te nemen, waardoor de algehele efficiëntie van gegevensbeheer en ontwikkeling verbetert.
Uitdagingen en beperkingen aanpakken
Hoewel CLL krachtige mogelijkheden biedt, is het belangrijk om bewust te zijn van de beperkingen:
- Kolomgebruik: CLL weerspiegelt voornamelijk de lineage van select statements in SQL code. Het kan zijn dat niet alle gegevensgebruiken zoals joins en filters worden vastgelegd.
- SQL Parsing: Fouten kunnen optreden tijdens lineage tracking, vooral met complexe SQL-structuren of bij het gebruik van Python-modellen binnen de lineage, die dbt mogelijk niet volledig parseert.
Conclusie
Column-Level Lineage in dbt Explorer vertegenwoordigt een belangrijke vooruitgang in data lineage tracking, waardoor analyseteams met meer precisie en vertrouwen door data pipelines kunnen navigeren. Door gedetailleerde inzichten te bieden in de gegevensstroom op een granulair niveau, ondersteunt CLL kritieke taken zoals debugging, effectbeoordeling en gezamenlijke besluitvorming.
Voor analysetechnici en data-analisten die hun dbt-workflows willen optimaliseren en de betrouwbaarheid van gegevens willen verbeteren, is het verkennen van Column-Level Lineage in dbt Explorer niet alleen een aanbeveling - het is een strategisch voordeel.
Je kunt meer lezen in de speciale dbt docs pagina.

Een kolom sorteren op basis van een andere kolom in Power BI

Sorteren met een parameter (in Tableau)