Door Jules van den Boogaard op 4 Jun, 2025

Data lakes beloven schaalbaarheid, flexibiliteit en kosteneffectiviteit in vergelijking met traditionele data warehouses. Maar als je grote hoeveelheden ongestructureerde bestanden, dubbele tabellen en ongedocumenteerde pijplijnen hebt, is je "meer" een moeras geworden en heb je problemen met je data lake.
Hier zijn vijf redenen waarom je data lake mogelijk faalt, samen met duidelijke, uitvoerbare stappen die je kunt nemen om te voorkomen dat je data lake een moeras wordt.
1. Gebrek aan metadata governance (Je weet niet wat er is)
Wat gaat er mis:
- Geen catalogus
- Geen eigenaarschap
- Gebrek aan duidelijke documentatie.
- 10 versies van dezelfde "klant" dataset met verschillende schema's.
Hoe los je het op?
- Implementeer governance tools zoals Unity Catalog (Databricks) of Microsoft Purview (Azure) om je metadata duidelijk te organiseren.
- Neem naamgevingsconventies aan en gebruik (indien mogelijk) tagging voor eigenaarschap.
- Implementeer updates van je metadata in je pijplijn en automatiseer dit proces.
2. Vasthouden aan ETL in plaats van ELT
Wat gaat er mis?
- Gegevens worden getransformeerd voordat ze landen.
- Geen behoud van originele ruwe gegevens.
- Permanent gegevensverlies door mislukte processen.
Hoe los je het op?
- Schakel over op een ELT-strategie waarbij ruwe gegevens eerst worden geland in formaten zoals Parquet of Delta Lake. Transformaties moeten dan downstream plaatsvinden.
- Gebruik de versiebeheer- en terugdraaifuncties van Delta Lake om de integriteit van gegevens te waarborgen.
- Beheer transformaties in tools zoals DBT of Databricks Notebooks/Workflows om de debugging-mogelijkheden te verbeteren.
3. Je Lake gebruiken als een file dump
Wat gaat er mis:
- Ongestructureerde, gemengde bestandsformaten die chaos veroorzaken.
- Regelmatig opgeblazen opslag en slechte queryprestaties.
- Moeite om consistentie te behouden.
Hoe los je het op?
- Standaardiseer uw gegevensopslag met formaten zoals Delta, Parquet of ORC.
- Gebruik partitionering op geselecteerde tabellen om de queryprestaties te verbeteren en de kosten in balans te houden.
- Introduceer geautomatiseerde schemavalidatie en null-controles om de gegevenskwaliteit bij aankomst te handhaven.
4. Ontbrekende lineage en logging
Wat gaat er mis:
- Moeite met het traceren van gegevensbronnen.
- Probleemoplossing is complex en tijdrovend.
- Afhankelijkheden zijn moeilijk te beheren en debuggen.
Hoe het op te lossen:
- Gebruik lineage-bewuste transformatietools zoals DBT om automatisch de lineage van gegevens op te sporen en weer te geven.
- Integreer monitoring en audit logging via Azure Data Factory of Databricks.
- Onderhoud je transformatielogica binnen Git, om traceerbaarheid en verantwoordelijkheid te behouden.
5. Niemand gebruikt het eigenlijk
Wat gaat er mis:
- Analisten blijven spreadsheets gebruiken.
- Stakeholders vertrouwen sterk op dashboard exports in plaats van directe queries.
- Algemeen wantrouwen in de nauwkeurigheid en betrouwbaarheid van het data lake.
Hoe het op te lossen:
- Ontwikkel intuïtieve semantische lagen bovenop gecureerde gegevens met behulp van dbt MetricFlow of Power BI.
- Leid uw gebruikers naar de duidelijk gedefinieerde en betrouwbare "gouden-niveau" dataset.
- Richt u op grondige documentatie en training om het vertrouwen van de gebruiker op te bouwen en de bruikbaarheid in uw hele organisatie te garanderen.
Conclusie: Bouw geen moeras
Het creëren van een succesvol data lake vergt iets meer inspanning dan alleen het dumpen van bestanden in opslag. Het vereist structuur, governance, lineage, bruikbaarheid en duidelijkheid. Als je meer aanvoelt als een moeras, moet je deze vereisten opnieuw bekijken. Anders wordt je dataplatform zeker niet volledig benut en heb je problemen met je datameer. Sommige lezers is het misschien al opgevallen dat een goed beheerd data lake erg lijkt op een data lake house. Een combinatie van een traditioneel datawarehouse en een data lake. Als je data lake niet de resultaten oplevert die je wilt, kan het de moeite waard zijn om te kijken naar de implementatie van een volledige data lakehouse oplossing.

6 tips om je Tableau dashboard sneller te maken
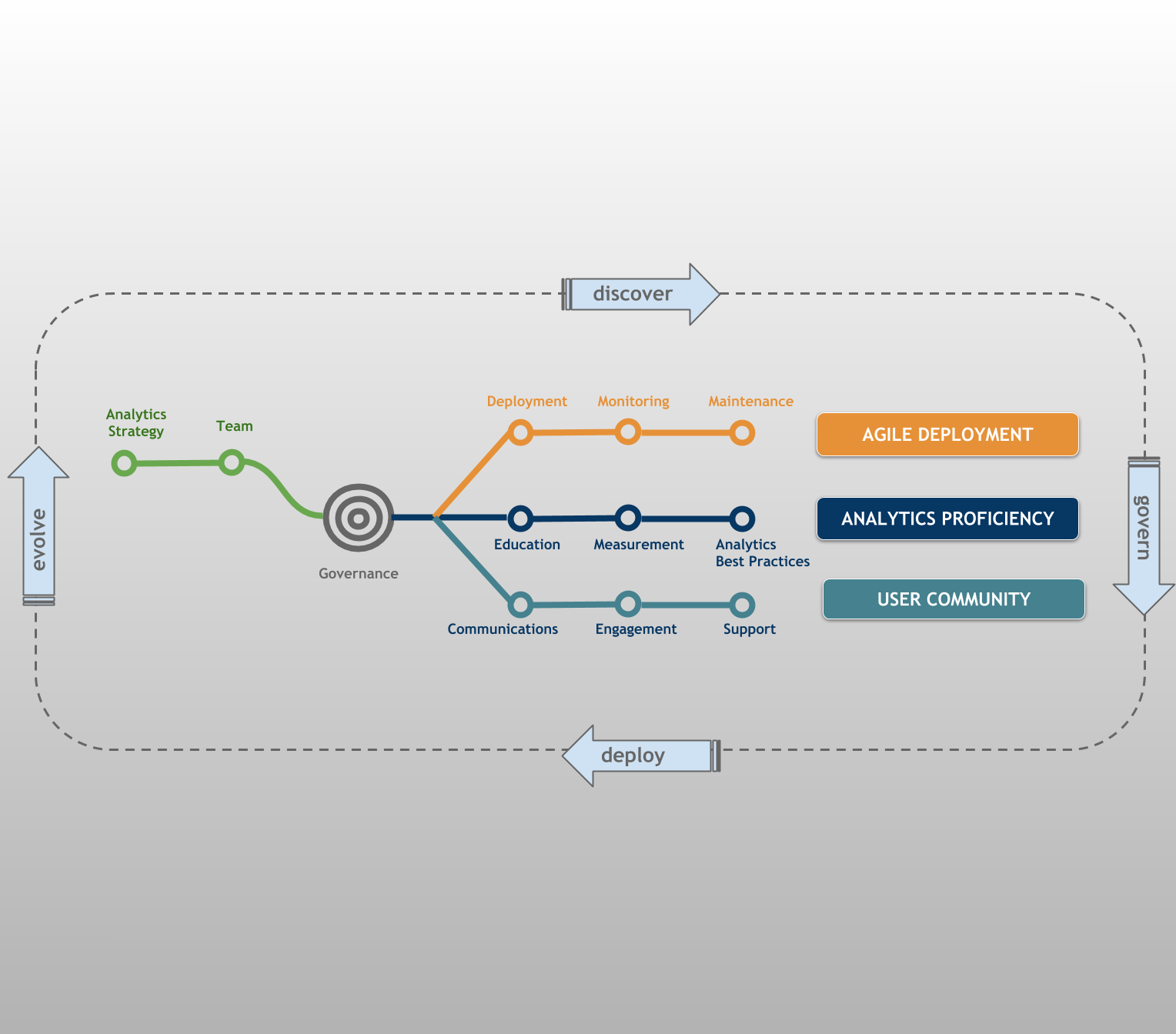
Starten met jouw datacultuur? Haal volledige waarde uit je data