
By Eloi Sanchez on 15 Aug, 2025
The Artificial Intelligence (AI) boom is a reality. Currently, it feels as if you are lagging behind and becoming obsolete if your company is not implementing AI both for internal and external products. Therefore, you may be considering starting to leverage the power of AI yourself. However, there is a crucial thing (and role) you must take into account!
What does AI need?
First of all, there is something that must be clear, AI and Machine Learning (ML) models are not sentient. They are not smart, independent beings that will generate the perfect answers to all your questions, even if they are designed properly. Instead, these models, regardless of their architecture, must fit some parameters (what we call training) that should be tuned in a way that provides the correct answers to the questions you intend to ask. In the case you are using a pre-trained model, it will act as an intermediary that fetches certain types of data sources to generate their answer. Regardless of the specifics of the situation, you can see that data is fundamental for any model to work
The importance of Data Engineers
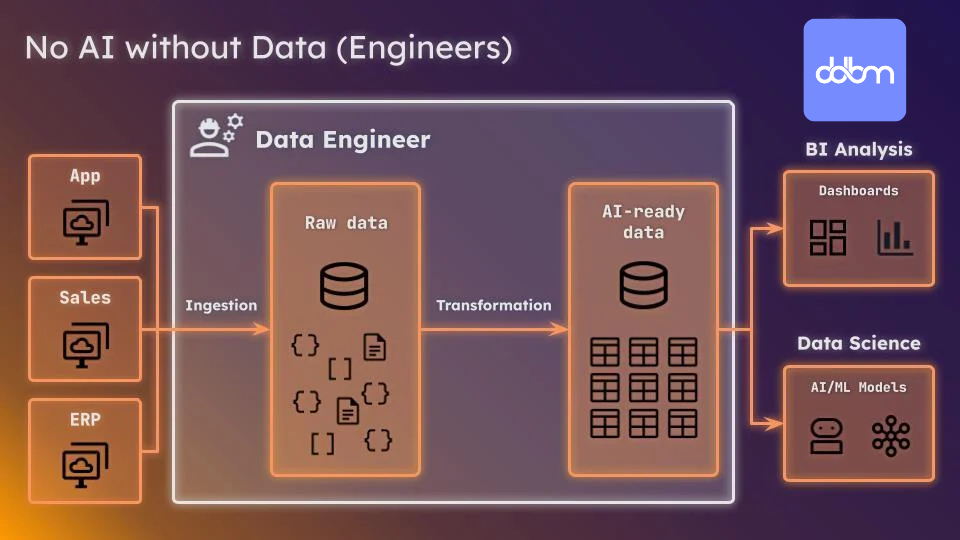
So, now that we have established a solid foundation of clean and usable data as the fundamental block that drives AI models, we need to ask what we have to do to bring your company to be ready for AI. Here is where the Data Engineers appear! This is the role that will create all the processes and infrastructure needed for you to take advantage of your data. Here is a nice diagram summarizing everything:

Let's analyze the steps we need to take into account with a bit more detail.
Ingestion
In order to have data for your models, it has to be ingested. There are multiple valid ways of doing so, be it with custom scripts, paid software (like Fivetran), open software (like data load tool). In this step, data will come from your sources (Salesforce, Exact Online, Stripe…) into your database. We cannot stop here though! This data will most likely come in in a raw format and will need to be processed in order to become useful.
Transformation
Here comes a combination of small steps that transform your raw data into organized, understandable and readily usable data. Again, many tools and methodologies can be used in order to perform this steps. There are code-heavy tools (like dbt) as well as no-code alternatives (like Alteryx or Coalesce) that will allow you to perform the data transformation in an organized and scalable way. Essentially, you can see this as a refining process of a raw material, where you extract a raw rock mineral (your raw data) and transform it to obtain the specific compound you are looking for (your data clean and ready to use).
Orchestration
The scheduling also tends to be essential, since you may require your model to be updated with the most recent data. This specific part is usually referred to as pipeline orchestration and, in short, it includes the infrastructure needed so that your ingestion and transformation steps are triggered at a schedule, ensuring that the data your BI users or models are using is up to date.
Finally, once we have a set of well-defined, organized and meaningful tables with up to date information, we are ready for our Data Scientists to start developing models that could be used internally or externally.
The Semantic Layer
However, if you would like to use the typical out-of-the-box Large Language Models that many companies provide, an extra intermediary layer is needed between your final data and the model. This layer is called the Semantic Layer, and it can be different depending on what specific model you are trying to use. Regardless, the objective of this Semantic layer is always the same: it provides context to the model so that it can understand your data, allowing it to search through it to find your answers. Typically, it would include information such as metrics definitions, domain specific knowledge or descriptions of tables and columns.
Take home message
Therefore before you start working with AI, you need AI-ready data, and to perform all the steps above you will need Data Engineers. Data Engineers are the foundation of any data stack. They make sure data products (dashboards, predictive models, chatbots…) are working. Without data (engineers) there are no data products.
Unless you are in a place where a solid data infrastructure has been deployed and is properly maintained, you can forget about building anything related to AI. Instead, you should focusing on building a competent data team that can provide you with AI-ready data. Only then you can start thinking about fancy dashboards, models or tools that you can show to your clients or your C-suite.
After all, having good data is not only a good-to-have when working with AI, it is essential.
If you would like to level up your company with AI and you are unsure if your data stack is ready, contact us!
Share this
Previous story
← Being comfortable within cloud environments
5 Problems with your data lake, and how to solve them

5 Problems with your data lake, and how to solve them
4 Jun, 2025
2
min read
Apache Airflow vs Dagster for Data Orchestration

Apache Airflow vs Dagster for Data Orchestration
19 Nov, 2024
3
min read
Understanding the Differences Between Several Data Roles

Understanding the Differences Between Several Data Roles
15 Mar, 2024
2
min read



